缓存失效问题被认为是计算机科学中最难的两件事之一,这篇文章来自翻译,内容主要包括缓存级别与缓存更新常见的几种模式。
缓存应用模式
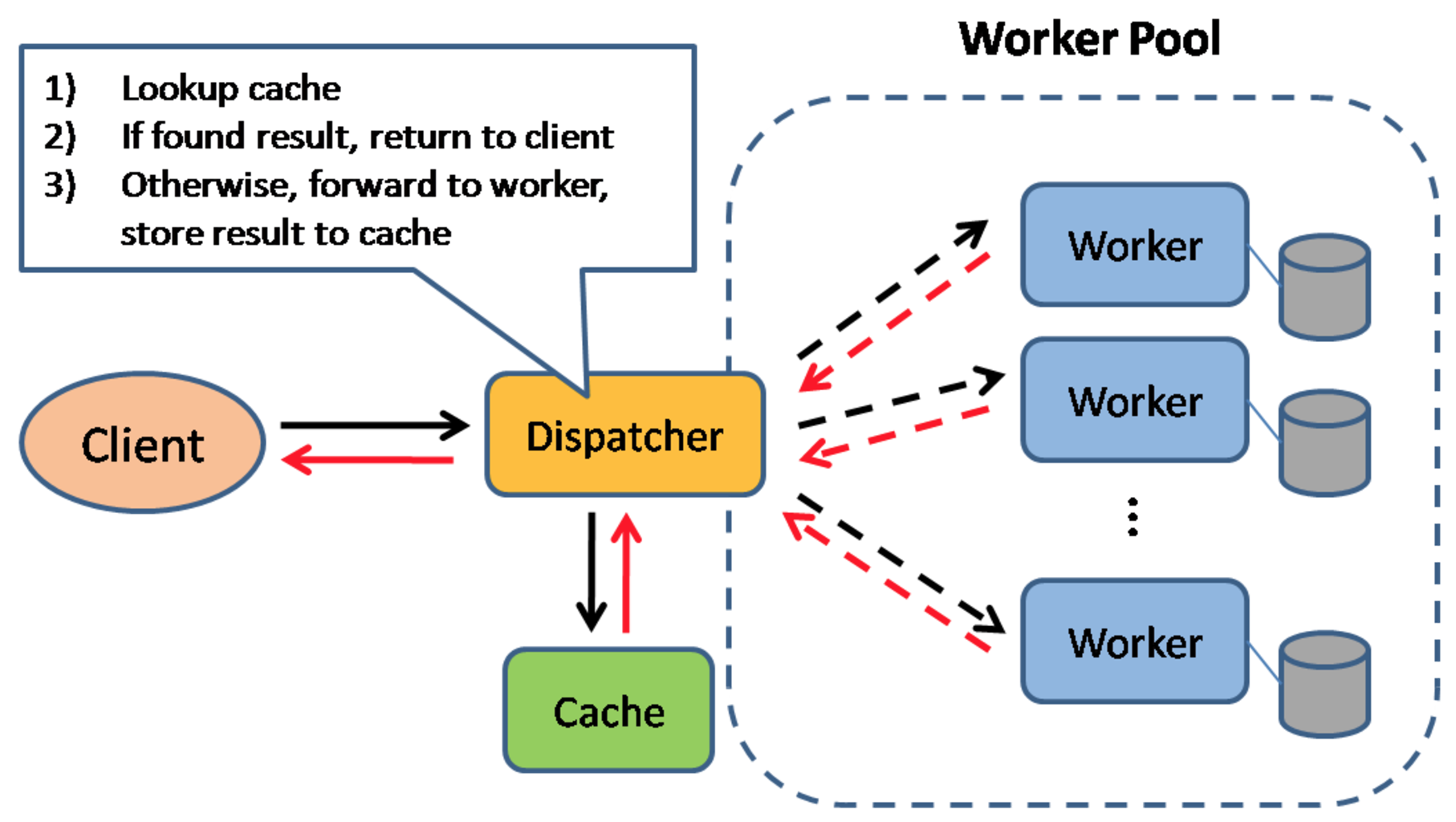
常见缓存应用模式
缓存常用来加快页面的加载速度,减少服务器或数据库服务的负载。缓存应用的常见模式如上图所示:
- 检索缓存,尝试查找之前相同请求的执行结果,如果找到了则返回,省去了重新执行的步骤;
- 如果缓存未命中,则重新执行计算逻辑并将结果保存至缓存;
数据库常常得益于对均匀分布的数据的读写,但是热点数据使得这种均匀被打破,从而出现了系统瓶颈。通过数据库服务前置缓存服务,可以有效吸收不均匀的负载和抵挡流量高峰。
缓存级别
缓存级别关注的问题是在什么时候做缓存(When)以及在什么地方做缓存(Where),下面介绍几种常见的缓存级别。
客户端缓存
缓存可以存储在客户端(操作系统或浏览器、服务端、或者是独立的缓存系统中。
CDN缓存
CDN也可以被认为是一种缓存。
Web服务器缓存
反向代理或者像Varnish这样的缓存服务可以直接保存静态的或动态的缓存内容。Web服务器也可以缓存请求直接响应客户端从而避免请求再次触达应用。
数据库缓存
我们的数据库服务在默认的配置或者稍微针对通用场景进行优化的情况下通常包含不同级别的缓存,针对特定的使用场景进行适当的调整可以进一步提高性能。
应用缓存
像Memcached和Redis这种内存key-value缓存服务,通常是置于应用和数据库服务之间,因为数据存储在内存中,因此这要比将数据存储在磁盘的数据库要快的多。但是内存与磁盘相比往往受限于空间,因此类似LRU(Least Recently Used)这种缓存淘汰算法应运而生,他们将相对较少访问的”冷”数据从内存置换出来将访问频率较高的“热”数据放入内存(将内存的使用价值最大化,译者注)。
Redis还有很多其他的功能,包括:
- 持久化选项;
- 内建数据结构(如sets、lists);
下面是针对数据库查询级别和对象级别的一般缓存:
- 行级缓存;
- 查询级别缓存;
- 完全序列化的缓存;
- 渲染后的HTML缓存;
值得一提的是,我们通常要避免文件级别的缓存,因为基于文件的缓存常常难于扩展和维护。
查询级别缓存:
每当我们查询数据库的时候,将查询(比如SQL)进行hash并作为key和查询结果关联存储,这种方法会遇到缓存过期的问题:
- 对于复杂的查询很难删除缓存的结果;
- 缓存粒度较大,如果查询结果中只有丁点数据被更新,则整个查询都要过期;
对象级别缓存:
对象级别缓存是将数据看做对象:
- 如果数据被修改则将数据从缓存中移除;
- 使用异步的任务来更新缓存;
对象级别的缓存建议的使用场景:
- 用户会话;
- 渲染后的页面;
- 活动流;
- 用户图形数据;
缓存更新问题
因为内存受限于空间缓存只能存储有限的数据,因此我们需要决定在我们的应用场景中,使用何种缓存更新策略,下面介绍几种常见的模式。
Cache-Aside
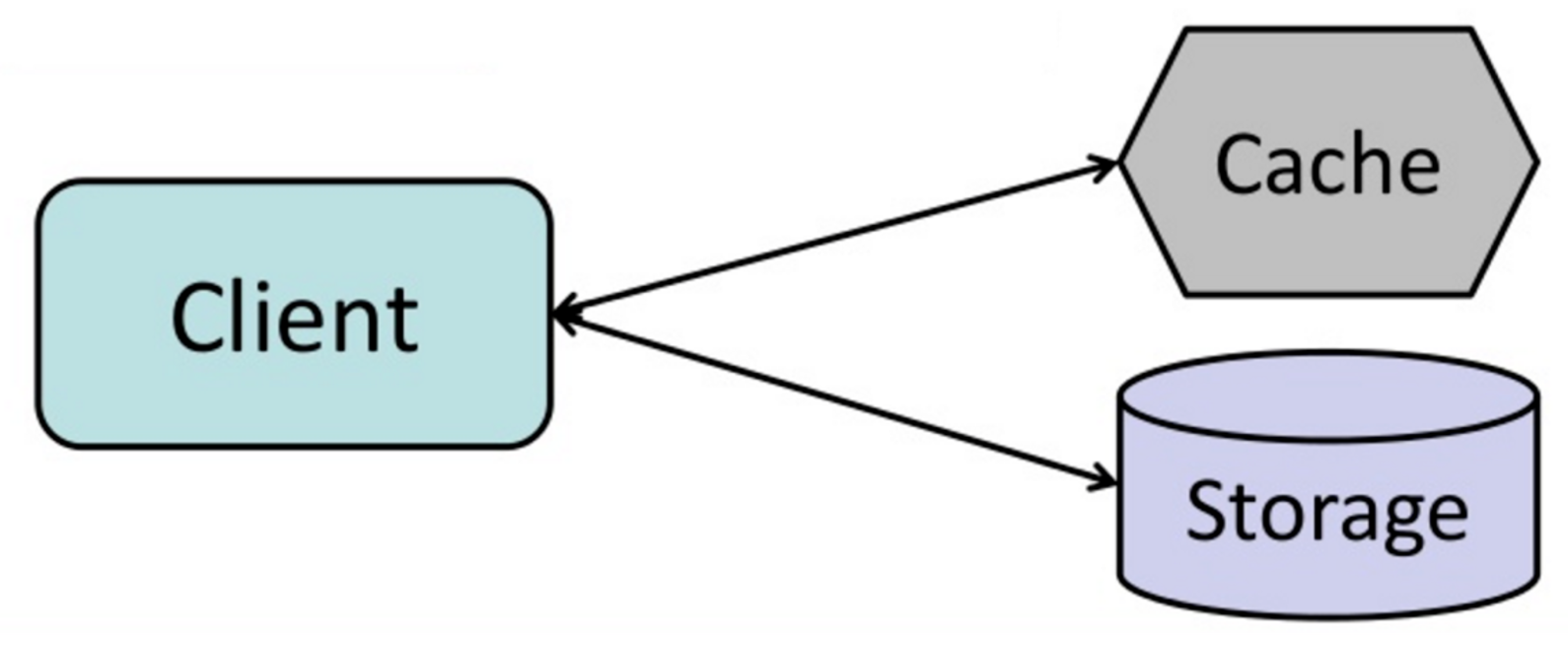
Cache-Aside模式
应用负责基于存储读写数据,缓存不直接和存储打交道,应用的行为如下:
- 检索缓存,缓存没有命中;
- 从数据库加载数据;
- 将数据更新至缓存;
- 返回结果;
代码示例如下:
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
cache.set(key, json.dumps(user))
return user
这种模式的缺点如下:Memcached通常被应用于这种方式,这种模式对于接下来的数据读取将非常快,Cache-Aside也叫做延迟加载,只有需要的数据被缓存,避免不需要的数据占用缓存空间。
- 每次缓存没命中都增加系统之间的交互,这将会增加响应延迟;
- 当对应数据库中的数据被更新之后将出现脏数据问题,这个问题可以通过设置过期时间(TTL)来缓解,当时间过期将发生强制更新缓存;
- 当一个节点坏了之后,新的节点代替旧的节点,这个时候将出现大量的缓存穿透问题;
Write-Though
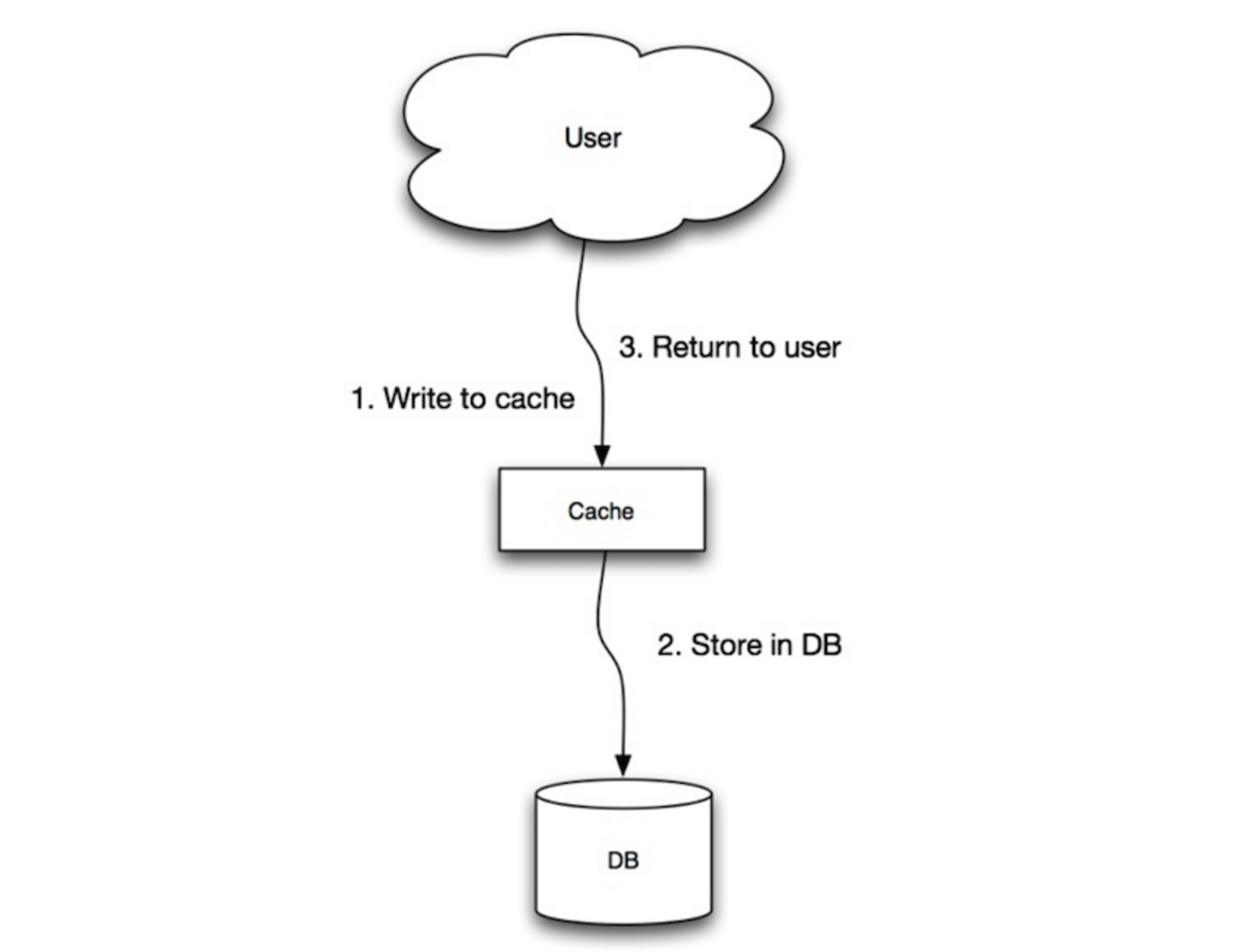
Write-Though模式
应用将缓存作为主要存储,读写都直接和缓存打交道,缓存负责基于存储进行读写:
- 应用基于缓存添加或删除记录;
- 缓存同步地将记录写入存储;
- 返回;
应用代码示例:
set_user(12345, {"foo":"bar"})
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)
Write-Though对于所有的写操作都是比较慢的,但是对于读来说很快,用户通常需要容忍写延迟,但是不会出现脏数据。
这种模式的缺点如下:
- 由于failure或者scaling带来的新增节点的时候,新增节点在下次更新数据之前将没有数据,这个问题可以结合Cache-Aside模式来缓解;
- 对于很多写入的数据将永远不会读取到,这个问题可以通过设置过期时间解决;
Write-Behind(Write-Back)
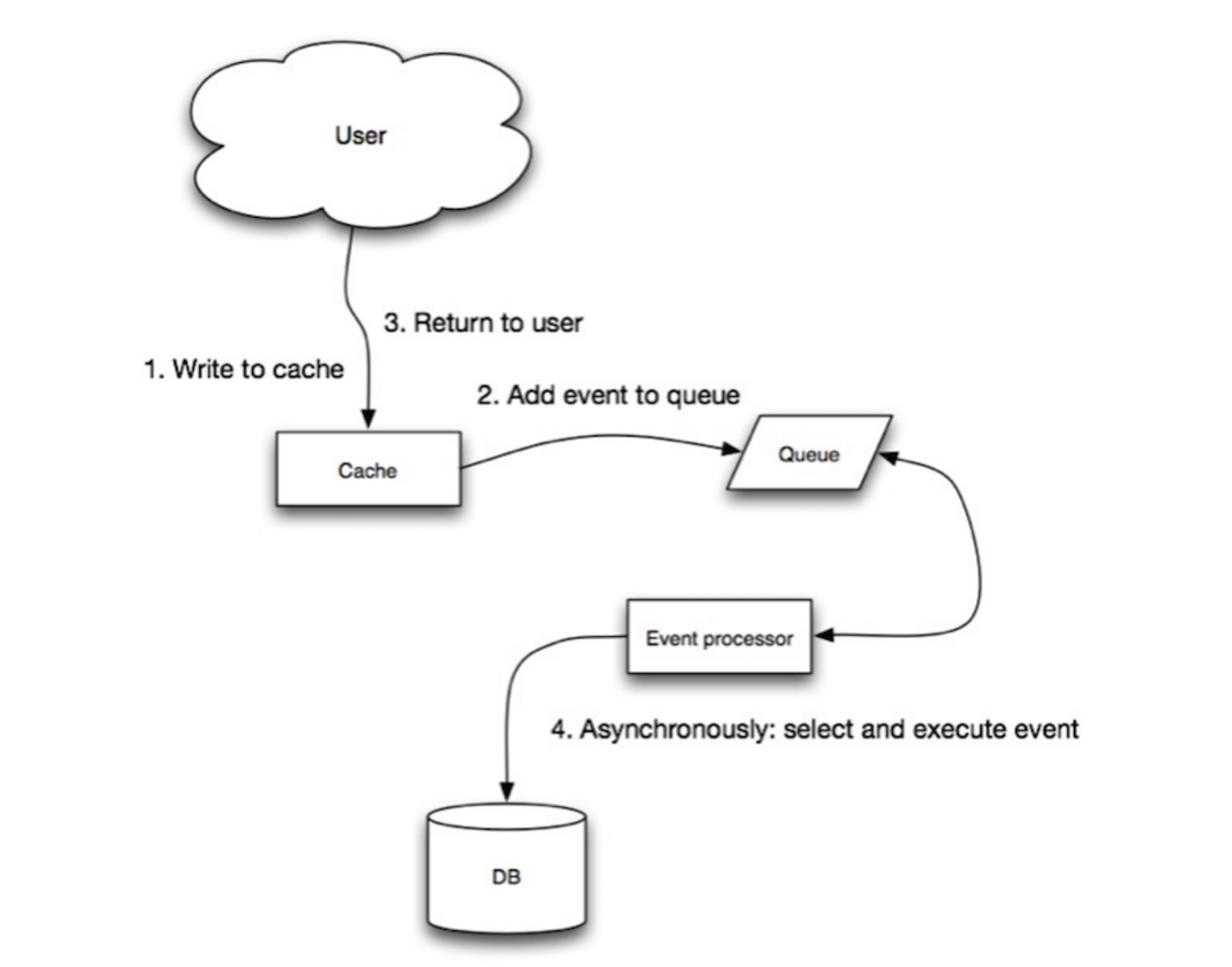
Write-Behind模式
在这种模式下,应用的行为如:
- 直接读写缓存;
- 写操作通知任务来异步进行更新;
这种模式的缺点如下:
- 如果在数据被更新到存储之前缓存挂了,则数据将会丢失;
- 实现起来比Write-Though和Cache-Aside模式更为复杂;
Refresh-Ahead
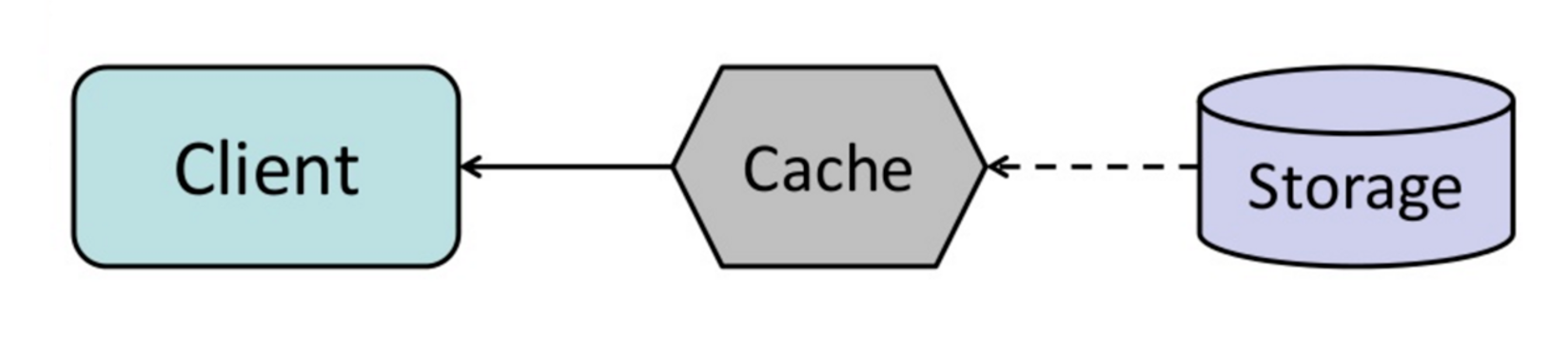
Refresh-Ahead模式
我们可以配置缓存自动在最近访问的数据过期之前更新它们,如果可以准确预测将要访问的数据,Refresh-Ahead模式可以有效地减少读写的延迟。
这种模式的缺点如下:
- 如果预测数据不准确,则比不做什么更有损性能;
缓存的缺点
一种解决方案通常会带来一些问题,我们来看看引入缓存带来的问题:
- 缓存的引入带来了一致性问题,我们需要处理缓存中的数据与原数据不一致的问题;
- 缓存的引入增加了软件架构的复杂性;;
- 缓存过期是个难题,这个问题主要体现在何时更新缓存上;
扩展阅读
- From cache to in-memory data grid
- Scalable system design patterns
- Introduction to architecting systems for scale
- Scalability, availability, stability, patterns
- Scalability
- AWS ElastiCache strategies
- Wikipedia




