一、前言
本次分享我们来共同探讨JUC包中一些有意思的类,包含AtomicLong & LongAdder,ThreadLocalRandom原理。
二、AtomicLong & LongAdder
2.1 AtomicLong 类
AtomicLong是JUC包提供的原子性操作类,其内部通过CAS保证了对计数的原子性更新操作。
大家可以翻看源码发现内部是通过UnSafe(rt.jar)这个类的CAs操作来保证对内部的计数器变量 long value进行原子性更新的,比如JDK8中:
1 | public final long incrementAndGet() { |
2 | return unsafe.getAndAddLong(this, valueOffset, 1L) + 1L; |
其中unsafe.getAndAddLong的代码如下:
1 | public final long getAndAddLong(Object paramObject, long paramLong1, long paramLong2) |
6 | l = getLongVolatile(paramObject, paramLong1);//(1) |
7 | } while (!compareAndSwapLong(paramObject, paramLong1, l, l + paramLong2));//(2) |
可知最终调用的是native 方法compareAndSwapLong原子性操作。
当多个线程调用同一个AtomicLong实例的incrementAndGet方法后,多个线程都会执行到unsafe.getAndAddLong方法,然后多个线程都会执行到代码(1)处获取计数器的值,然后都会去执行代码(2),如果多个线程同时执行了代码(2),由于CAS具有原子性,所以只有一个线程会更新成功,然后返回true从而退出循环,整个更新操作就OK了。其他线程则CAS失败返回false,则循环一次在次从(1)处获取当前计数器的值,然后在尝试执行(2),这叫做CAS的自旋操作,本质是使用Cpu 资源换取使用锁带来的上下文切换等开销。
2.2 LongAdder类
AtomicLong类为开发人员使用线程安全的计数器提供了方便,但是AtomicLong在高并发下存在一些问题,如上所述,当大量线程调用同一个AtomicLong的实例的方法时候,同时只有一个线程会CAS计数器的值成功,失败的线程则会原地占用cpu进行自旋转重试,这回造成大量线程白白浪费cpu原地自旋转。
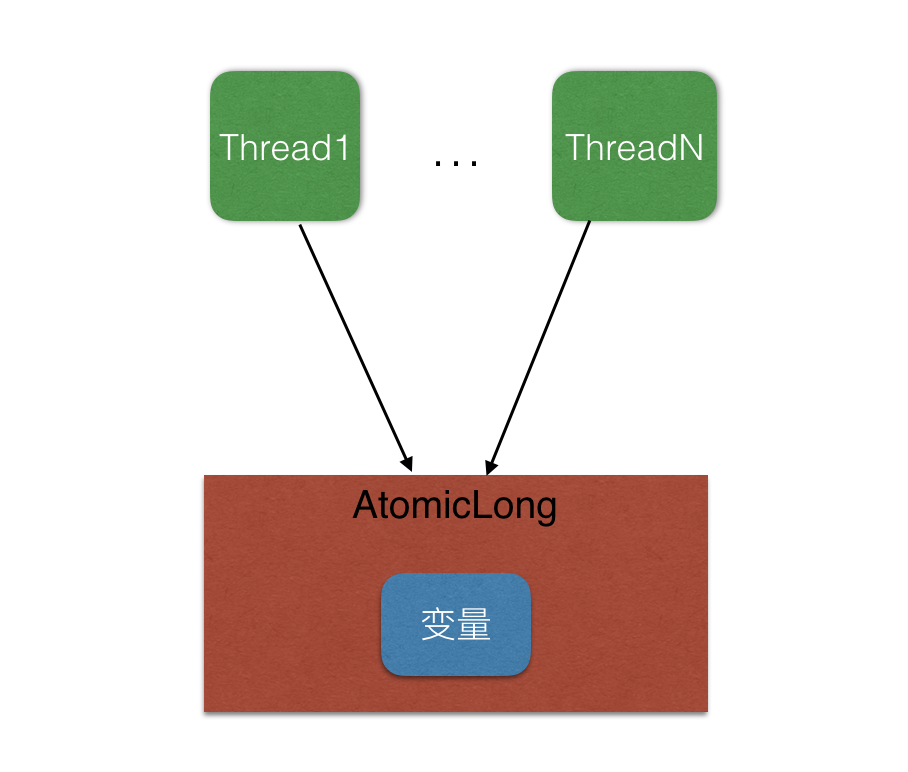
在JDK8中新增了一个LongAdder类,其采用分而治之的策略来减少同一个变量的并发竞争度,LongAdder的核心思想是把一个原子变量分解为多个变量,让同样多的线程去竞争多个资源,这样竞争每个资源的线程数就被分担了下来,下面通过图形来理解下两者设计的不同之处:
如上图AtomicLong是多个线程同时竞争同一个原子变量。
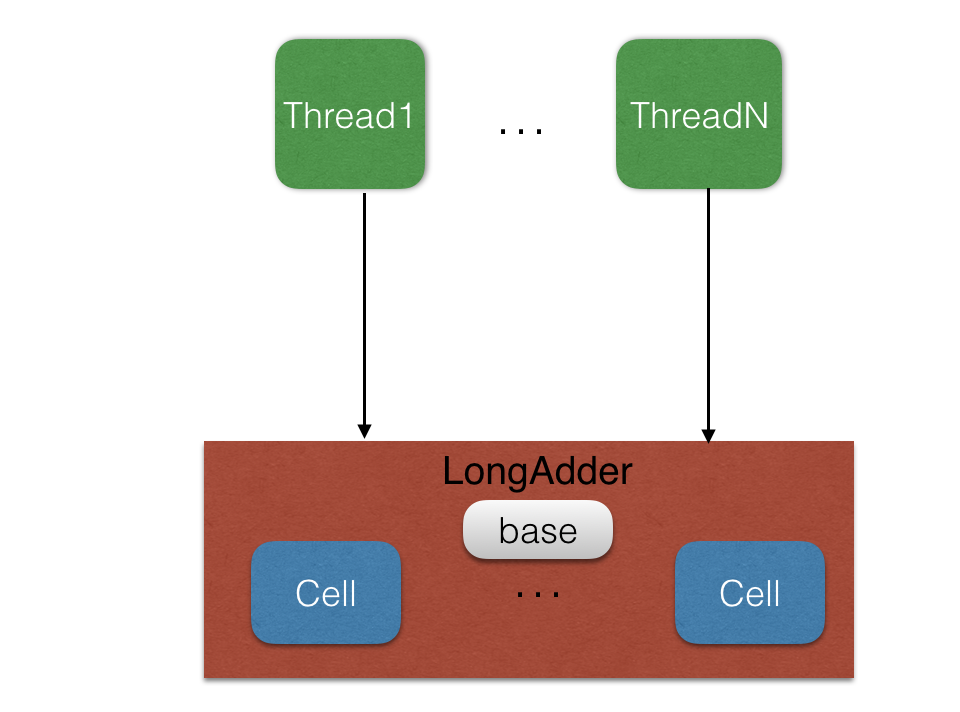
如上图LongAdder内部维护多个Cell变量,在同等并发量的情况下,争夺单个变量更新操作的线程量会减少,这是变相的减少了争夺共享资源的并发量。
下面我们首先看下Cell的结构:
01 | @sun.misc.Contended static final class Cell { |
03 | Cell(long x) { value = x; } |
04 | final boolean cas(long cmp, long val) { |
05 | return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val); |
09 | private static final sun.misc.Unsafe UNSAFE; |
10 | private static final long valueOffset; |
13 | UNSAFE = sun.misc.Unsafe.getUnsafe(); |
14 | Class<?> ak = Cell.class; |
15 | valueOffset = UNSAFE.objectFieldOffset |
16 | (ak.getDeclaredField("value")); |
17 | } catch (Exception e) { |
LongAdder维护了一个延迟初始化的原子性更新数组(默认情况下Cell数组是null)和一个基值变量base,由于Cells占用内存是相对比较大的,所以一开始并不创建,而是在需要时候在创建,也就是惰性 创建。
当一开始判断cell数组是null并且并发线程较少时候所有的累加操作都是对base变量进行的,这时候就退化为了AtomicLong。cell数组的大小保持是2的N次方大小,初始化时候Cell数组的中Cell的元素个数为2,数组里面的变量实体是Cell类型。
当多个线程在争夺同一个Cell原子变量时候如果失败并不是在当前cell变量上一直自旋CAS重试,而是会尝试在其它Cell的变量上进行CAS尝试,这个改变增加了当前线程重试时候CAS成功的可能性。最后获取LongAdder当前值的时候是把所有Cell变量的value值累加后在加上base返回的,如下代码:
02 | Cell[] as = cells; Cell a; |
05 | for (int i = 0; i < as.length; ++i) { |
06 | if ((a = as[i]) != null) |
如上代码可知首先把base的值赋值给sum变量,然后通过循环把每个cell元素的value值累加到sum变量上,最后返回sum.
其实这是一种分而治之的策略,先把并发量分担到多个原子变量上,让多个线程并发的对不同的原子变量进行操作,然后获取计数时候在把所有原子变量的计数和累加。
思考问题:
性能对比,这里有一个文章 http://blog.palominolabs.com/2014/02/10/java-8-performance-improvements-longadder-vs-atomiclong/
三、 Random & ThreadLocalRandom
3.1 Random类原理及其局限性
在JDK7之前包括现在java.util.Random应该是使用比较广泛的随机数生成工具类,下面先通过简单的代码看看java.util.Random是如何使用的:
01 | public class RandomTest { |
02 | public static void main(String[] args) { |
05 | Random random = new Random(); |
06 | //(2)输出10个在0-5(包含0,不包含5)之间的随机数 |
07 | for (int i = 0; i < 10; ++i) { |
08 | System.out.println(random.nextInt(5)); |
01 | public int nextInt(int bound) { |
04 | throw new IllegalArgumentException(BadBound); |
如上代码可知新的随机数的生成需要两个步骤
下面看下next()代码:
01 | protected int next(int bits) { |
02 | long oldseed, nextseed; |
03 | AtomicLong seed = this.seed; |
08 | nextseed = (oldseed * multiplier + addend) & mask; |
10 | } while (!seed.compareAndSet(oldseed, nextseed)); |
12 | return (int)(nextseed >>> (48 - bits)); |
代码(6)使用原子变量的get方法获取当前原子变量种子的值
代码(7)根据具体的算法使用当前种子值计算新的种子
代码(8)使用CAS操作,使用新的种子去更新老的种子,多线程下可能多个线程都同时执行到了代码(6)那么可能多个线程都拿到的当前种子的值是同一个,然后执行步骤(7)计算的新种子也都是一样的,但是步骤(8)的CAS操作会保证只有一个线程可以更新老的种子为新的,失败的线程会通过循环从新获取更新后的种子作为当前种子去计算老的种子,这就保证了随机数的随机性。
代码(9)则使用固定算法根据新的种子计算随机数,并返回。
3.2 ThreadLocalRandom
Random类生成随机数原理以及不足:每个Random实例里面有一个原子性的种子变量用来记录当前的种子的值,当要生成新的随机数时候要根据当前种子计算新的种子并更新回原子变量。
多线程下使用单个Random实例生成随机数时候,多个线程同时计算随机数计算新的种子时候多个线程会竞争同一个原子变量的更新操作,由于原子变量的更新是CAS操作,同时只有一个线程会成功,那么CAS操作失败的大量线程进行自旋重试,而大量线程的自旋重试是会降低并发性能和消耗CPU资源的,为了解决这个问题,ThreadLocalRandom类应运而生。
01 | public class RandomTest { |
03 | public static void main(String[] args) { |
05 | ThreadLocalRandom random = ThreadLocalRandom.current(); |
07 | //(11)输出10个在0-5(包含0,不包含5)之间的随机数 |
08 | for (int i = 0; i < 10; ++i) { |
09 | System.out.println(random.nextInt(5)); |
如上代码(10)调用ThreadLocalRandom.current()来获取当前线程的随机数生成器。下面来分析下ThreadLocalRandom的实现原理。
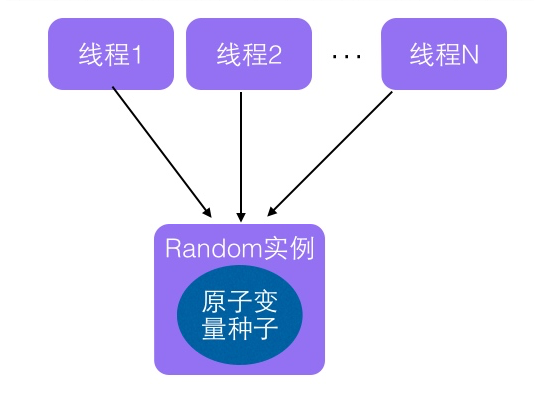
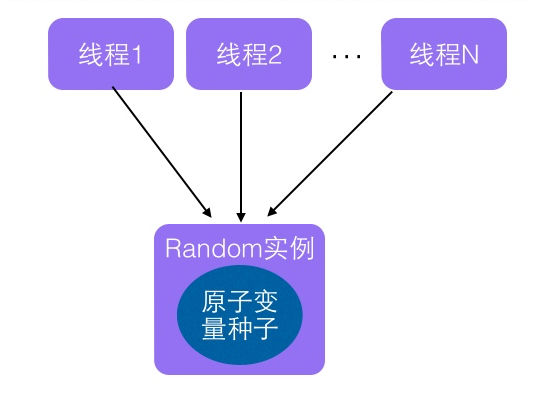
从名字看会让我们联想到ThreadLocal类。ThreadLocal通过让每一个线程拷贝一份变量,每个线程对变量进行操作时候实际是操作自己本地内存里面的拷贝,从而避免了对共享变量进行同步。实际上ThreadLocalRandom的实现也是这个原理。Random的缺点是多个线程会使用原子性种子变量,会导致对原子变量更新的竞争,这个原理可以通过下面图来表达:
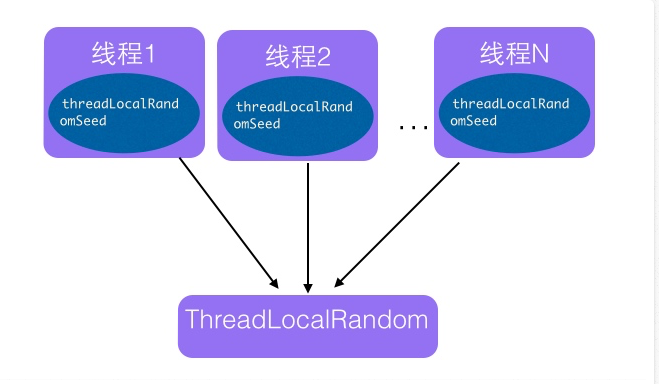
那么如果每个线程维护自己的一个种子变量,每个线程生成随机数时候根据自己本地内存中的老的种子计算新的种子,并使用新种子更新老的种子,然后根据新种子计算随机数,就不会存在竞争问题,这会大大提高并发性能,如下图ThreadLocalRandom原理可以使用下图表达:
Thread类里面有几个变量:
1 | /** The current seed for a ThreadLocalRandom */ |
2 | @sun.misc.Contended("tlr") |
3 | long threadLocalRandomSeed; |
5 | /** Probe hash value; nonzero if threadLocalRandomSeed initialized */ |
6 | @sun.misc.Contended("tlr") |
7 | int threadLocalRandomProbe; |
思考问题:
每个线程的初始种子怎么生成的
如果保障多个线程产生的种子不一样
四、总结
本文 是对拙作 Java并发编程之美 一书中相关章节的提炼。本文主要讲解了 AtomicLong的内部实现,以及存在的缺点,然后讲解了 LongAdder采用分而治之的策略通过使用多个原子变量减小单个原子变量竞争的并发度。然后简单介绍了Random,和其缺点,最后介绍了ThreadLocalRandom借用ThreadLocal的思想解决了多线程对同一个原子变量竞争锁带来的性能损耗。其实JUC包中还有其他一些经典的组件,比如fork-join框架等。