你可能没意识到Java对函数式编程的重视程度,看看Java 8加入函数式编程扩充多少功能就清楚了。Java 8之所以费这么大功夫引入函数式编程,原因有二:
- 代码简洁,函数式编程写出的代码简洁且意图明确,使用stream接口让你从此告别for循环。
- 多核友好,Java函数式编程使得编写并行程序从未如此简单,你需要的全部就是调用一下
parallel()方法。
这一节我们学习stream,也就是Java函数式编程的主角。对于Java 7来说stream完全是个陌生东西,stream并不是某种数据结构,它只是数据源的一种视图。这里的数据源可以是一个数组,Java容器或I/O channel等。正因如此要得到一个stream通常不会手动创建,而是调用对应的工具方法,比如:
- 调用
Collection.stream()或者Collection.parallelStream()方法 - 调用
Arrays.stream(T[] array)方法
常见的stream接口继承关系如图:
图中4种stream接口继承自BaseStream,其中IntStream, LongStream, DoubleStream对应三种基本类型(int, long, double,注意不是包装类型),Stream对应所有剩余类型的stream视图。为不同数据类型设置不同stream接口,可以1.提高性能,2.增加特定接口函数。
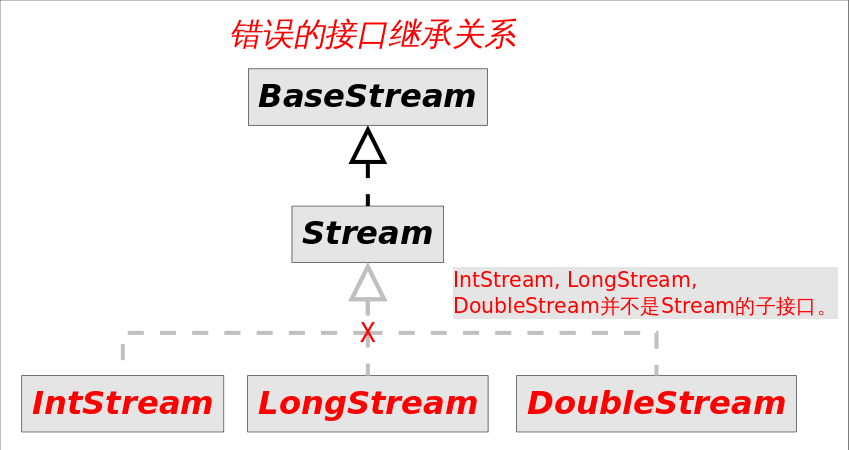
你可能会奇怪为什么不把IntStream等设计成Stream的子接口?毕竟这接口中的方法名大部分是一样的。答案是这些方法的名字虽然相同,但是返回类型不同,如果设计成父子接口关系,这些方法将不能共存,因为Java不允许只有返回类型不同的方法重载。
虽然大部分情况下stream是容器调用Collection.stream()方法得到的,但stream和collections有以下不同:
- 无存储。stream不是一种数据结构,它只是某种数据源的一个视图,数据源可以是一个数组,Java容器或I/O channel等。
- 为函数式编程而生。对stream的任何修改都不会修改背后的数据源,比如对stream执行过滤操作并不会删除被过滤的元素,而是会产生一个不包含被过滤元素的新stream。
- 惰式执行。stream上的操作并不会立即执行,只有等到用户真正需要结果的时候才会执行。
- 可消费性。stream只能被“消费”一次,一旦遍历过就会失效,就像容器的迭代器那样,想要再次遍历必须重新生成。
对stream的操作分为为两类,中间操作(intermediate operations)和结束操作(terminal operations),二者特点是:
- 中间操作总是会惰式执行,调用中间操作只会生成一个标记了该操作的新stream,仅此而已。
- 结束操作会触发实际计算,计算发生时会把所有中间操作积攒的操作以pipeline的方式执行,这样可以减少迭代次数。计算完成之后stream就会失效。
如果你熟悉Apache Spark RDD,对stream的这个特点应该不陌生。
下表汇总了Stream接口的部分常见方法:
| 操作类型 | 接口方法 |
|---|---|
| 中间操作 | concat() distinct() filter() flatMap() limit() map() peek() skip() sorted() parallel() sequential() unordered() |
| 结束操作 | allMatch() anyMatch() collect() count() findAny() findFirst() forEach() forEachOrdered() max() min() noneMatch() reduce() toArray() |
区分中间操作和结束操作最简单的方法,就是看方法的返回值,返回值为stream的大都是中间操作,否则是结束操作。
stream方法使用
stream跟函数接口关系非常紧密,没有函数接口stream就无法工作。回顾一下:函数接口是指内部只有一个抽象方法的接口。通常函数接口出现的地方都可以使用Lambda表达式,所以不必记忆函数接口的名字。
forEach()
我们对forEach()方法并不陌生,在Collection中我们已经见过。方法签名为void forEach(Consumer<? super E> action),作用是对容器中的每个元素执行action指定的动作,也就是对元素进行遍历。
// 使用Stream.forEach()迭代
Stream<String> stream = Stream.of("I", "love", "you", "too");
stream.forEach(str -> System.out.println(str));
由于forEach()是结束方法,上述代码会立即执行,输出所有字符串。
filter()
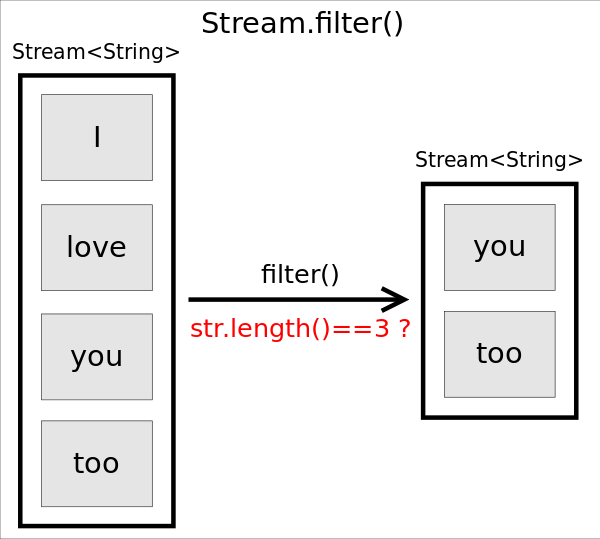
函数原型为Stream<T> filter(Predicate<? super T> predicate),作用是返回一个只包含满足predicate条件元素的Stream。
// 保留长度等于3的字符串
Stream<String> stream= Stream.of("I", "love", "you", "too");
stream.filter(str -> str.length()==3)
.forEach(str -> System.out.println(str));
上述代码将输出为长度等于3的字符串you和too。注意,由于filter()是个中间操作,如果只调用filter()不会有实际计算,因此也不会输出任何信息。
distinct()

函数原型为Stream<T> distinct(),作用是返回一个去除重复元素之后的Stream。
Stream<String> stream= Stream.of("I", "love", "you", "too", "too");
stream.distinct()
.forEach(str -> System.out.println(str));
上述代码会输出去掉一个too之后的其余字符串。
sorted()
排序函数有两个,一个是用自然顺序排序,一个是使用自定义比较器排序,函数原型分别为Stream<T> sorted()和Stream<T> sorted(Comparator<? super T> comparator)。
Stream<String> stream= Stream.of("I", "love", "you", "too");
stream.sorted((str1, str2) -> str1.length()-str2.length())
.forEach(str -> System.out.println(str));
上述代码将输出按照长度升序排序后的字符串,结果完全在预料之中。
map()
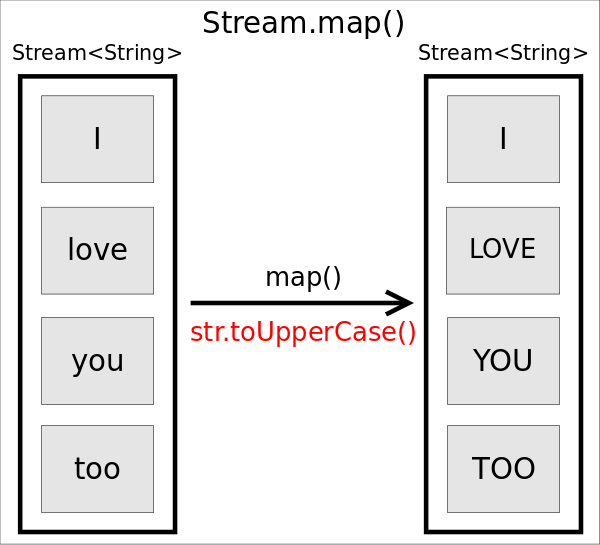
函数原型为<R> Stream<R> map(Function<? super T,? extends R> mapper),作用是返回一个对当前所有元素执行执行mapper之后的结果组成的Stream。直观的说,就是对每个元素按照某种操作进行转换,转换前后Stream中元素的个数不会改变,但元素的类型取决于转换之后的类型。
Stream<String> stream = Stream.of("I", "love", "you", "too");
stream.map(str -> str.toUpperCase())
.forEach(str -> System.out.println(str));
上述代码将输出原字符串的大写形式。
flatMap()
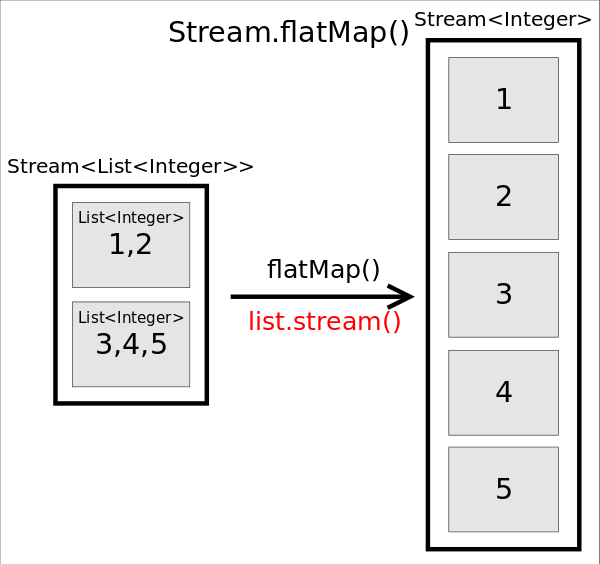
函数原型为<R> Stream<R> flatMap(Function<? super T,? extends Stream<? extends R>> mapper),作用是对每个元素执行mapper指定的操作,并用所有mapper返回的Stream中的元素组成一个新的Stream作为最终返回结果。说起来太拗口,通俗的讲flatMap()的作用就相当于把原stream中的所有元素都”摊平”之后组成的Stream,转换前后元素的个数和类型都可能会改变。
Stream<List<Integer>> stream = Stream.of(Arrays.asList(1,2), Arrays.asList(3, 4, 5));
stream.flatMap(list -> list.stream())
.forEach(i -> System.out.println(i));
上述代码中,原来的stream中有两个元素,分别是两个List<Integer>,执行flatMap()之后,将每个List都“摊平”成了一个个的数字,所以会新产生一个由5个数字组成的Stream。所以最终将输出1~5这5个数字。
结语
截止到目前我们感觉良好,已介绍StreamAPI理解起来并不费劲儿。如果你就此以为函数式编程不过如此,恐怕是高兴地太早了。下一节对Stream规约操作的介绍将刷新你现在的认识。
本文github地址,欢迎关注。




